
By Maulik Soneji
Gojek’s Data Engineering team is responsible for building solutions that help orchestrate data across the organisation. We, in turn, rely on Kafka to distribute events across various services, and new topics get added almost every day across different Kafka clusters. These clusters serve enormous throughputs, and we use our internal tools Beast and Sakaar pipelines for publishing data to BigQuery(BQ) and Google Cloud Storage(GCS) respectively.
In this blog, we explain the workings of Hodor, a tool designed to capture metrics in Kafka, BigQuery, and GCS for the benefit of our data warehouse developers.
Why build a new solution?
Given the scale at which Gojek operates, we strive to ensure we have enough metrics to base our decisions on.
Although the Beast and Sakaar pipelines used to sink data from Kafka to BigQuery and GCS buckets are reliable, we need to justify our claims by measuring various aspects of output data.
So we built Hodor.
Hodor is a Data Quality assessment tool that captures completeness, uniqueness and latency metrics from Kafka, BigQuery and GCS. These metric results are compared to provide a Quality score — which can be accessed by the users on a dashboard.
The main users of these metrics are Data Warehouse Developers, who are informed if the pipelines have high latency, duplicated or missing data in near real-time window. This helps the Data Engineering team to proactively backfill the data during issues, as opposed to getting to know about it from the users.
How does it work?
Hodor is built using Apache Beam programming model, where we can define the same pipeline code for batch and streaming.
Apache Beam under the hood
Just to make it easier to understand the terms used in the blog post, here’s a ready reckoner:
- Runner: Apache Beam abstracts the data processing pipeline by providing an API layer that utilises Runner as an execution engine to run the job
- Pipeline: All Beam programs run a pipeline that runs the job from start to finish. Here, you provide details about the runner and the entire pipeline of data from reading, transforming and writing data
- PCollection: A distributed data set that the beam pipeline operates on
- PTransform: A transformation task that takes in a PCollection and produces an output of PCollection objects
- Windowing: Divide a PCollection into one or more windows by logic provided in the windowing function.
Architecture
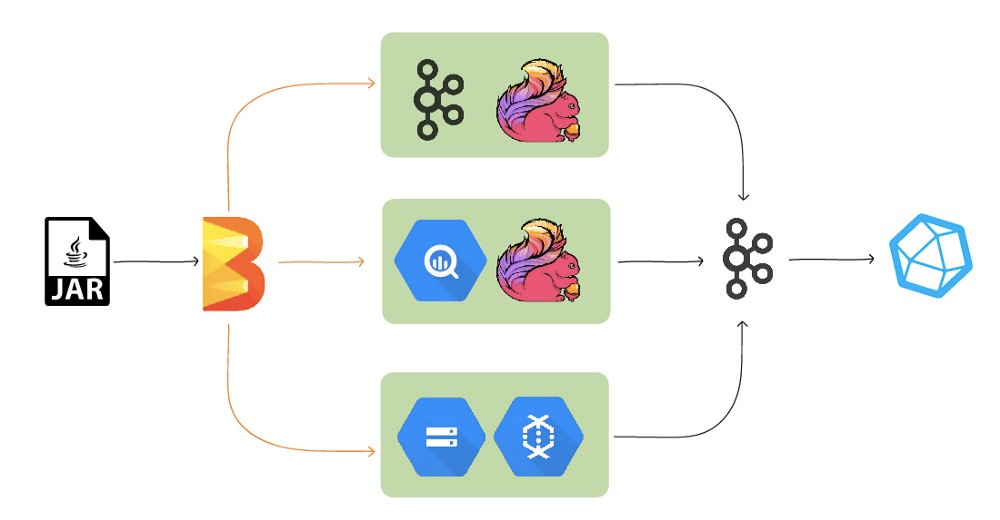
- Hodor uses Apache Flink(Kafka/BQ) and Google Dataflow(GCS) as Runner
- A Hodor job considers a time window of 10 minutes and pushes metrics related to latency, duplication, and data loss for each of this time window
- The job is begun by reading the configuration options and creating a pipeline that encapsulates the whole transformation
- As a first step of the pipeline, data is read from the source and a PCollection of input read is created from the source.
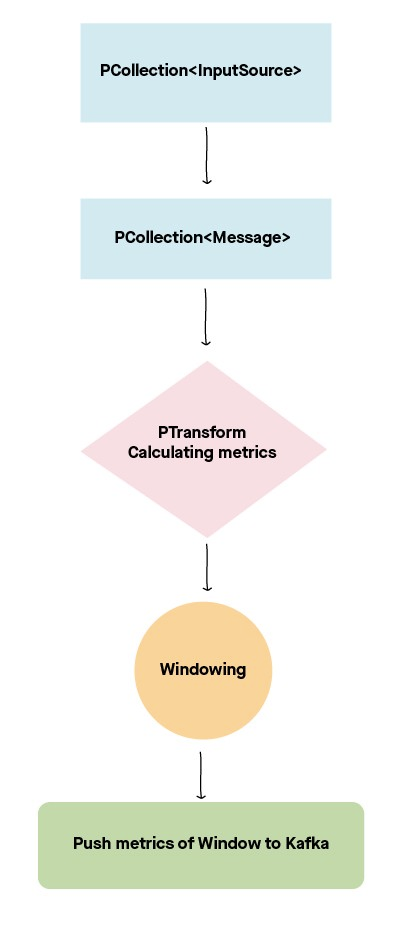
Since the sources are of different types (i.e., the messages in Kafka and Bigquery and Parquet formatted records in GCS), we convert the input PCollection to a PCollection of a common object Message so that each input source is processed the same way. Each Message has information like Source Kafka Topic, Partition, Event Timestamp, Processing Timestamp and MD5 Hash of the data.
This PCollection of Messages goes through a number of PTransform jobs that aggregate the data of a specific time window of data and grouping, based on the source Kafka topic.
Here’s the metrics that get calculated:
- Total count of messages
- Total count of unique topic, partition and offset combination
- Total count of unique messages by calculating the MD5 hash of each message
- Different percentiles of latencies by calculating difference between time when the message was published and the time when the message was processed by Kafka/Beast/Sakaar
These aggregated metrics are then windowed based on the event timestamp field and the metrics are pushed to an output Kafka topic.
In addition to windowing based on event timestamp, we can also add lateness tolerance to the window, so data that arrive late will be added to the correct window and metric for that window will be recalculated. This gives us the eventual consistency of metrics.
Lateness tolerance in the window makes sure that messages that arrive late are considered for the same time window that the message belongs to, and not based on when the message was consumed.
These metrics are then pushed to Influxdb, on which we create Grafana dashboard, that helps us create dashboards that informs our various stakeholders about the various aspects of data.
Deploying Hodor Jobs
The Hodor jobs are deployed on Kubernetes using a helm chart. Since we have automation in place, when we have a new Kafka topic, we automatically create a new Hodor Kafka Job. We also run the Bigquery and GCS jobs as Kubernetes cronjob that runs every 10 minutes.
Running Beam
We run Apache Beam version 2.15.0 with FlinkRunner and Google Dataflow Runner.
FlinkRunner
FlinkRunner is used for running Kafka and BigQuery jobs. We use Flink version 1.6.4 underneath as the runner.
As Kafka topics have different throughputs (and thus require different parallelism) we create one Kafka job per topic. Having one job per topic also enables us isolate any issues with a particular topic, as well as scale up the job as per requirement.
BigQuery jobs are run using BigQuery’s Storage API, and use BigQuery’s Job API to run the job. Flink is used only to collect the input data from various tables, and once the query processing is done in BigQuery, write the resultant metrics back to a Kafka topic.
We run BigQuery jobs at low parallelism as most of the heavy lifting is done by the BigQuery Job API.
DataflowRunner
Google Dataflow is a managed service provided by Google Cloud Services to transform data in batch as well as stream mode.
DataFlowRunner is used for running GCS jobs, and we run one Hodor job per Kafka cluster. In order to scale the job, we utilise Dataflow’s auto-scaling functionality to scale up the job when the throughput gets high.
The Issues We Ran Into
Any solution comes with a set of challenges that need to be looked into and tackled. With Hodor too, we had to troubleshoot quite a bit.
Intermittent No GCSFileSystem Found Exception
While running the GCS jobs on FlinkRunner, we observed that the job was failing intermittently while reading data from GCS. This was an issue (now fixed) in Beam where Filesystems are not properly registered in FlinkRunner. More details here.
This issue has been fixed by the community and it will be available in the upcoming 2.17.0 version of Beam. There are some workarounds available to use withNoSpilling() option if using FileIO API to read from GCS.
Submitting Job in Attached Mode
We are running the Hodor job on Flink in attached mode, which means Beam will keep the Hodor application running as long as the Flink job is running. Beam will keep polling the status of the job in the meantime, and let the application take action depending on the status.
Our Hodor jobs are deployed on Kubernetes, so when the Hodor job does not receive a heartbeat from Flink JobManager, it throws an error and Kubernetes restarts the process. This, in turn, results in the creation of two jobs, because Flink JobManager didn’t receive any signal to stop the job.
In order to resolve this issue, we added a shutdown hook to Hodor so that when the process is stopped, we send a message to Flink Jobmanager API to stop the job.
Different version of FlinkRunner Library
Having the same version of the FlinkRunner library as the version of Flink deployment is essential to run the job. FlinkRunner library utilises the Flink JobManager API to submit the job.
It turned out that we were using Flink version 1.8 locally to test the Hodor integration, and Flink Runner 1.8 library in Hodor. As expected things were running fine locally, but running the same job on production (which was using Flink Runner 1.6.4) gave a 404 error.
This was because the Flink runner library was trying to use the older API to submit the job.
Contributions from:
Zaki Indra Sukma, Arinda Arif, Anwar Hidayat, Shaurya Gupta, Kush Sharma, Maulik Soneji
That’s all from us for now folks!

