
By Yu-Xi Lim
This is the final post in a series on Gojek’s Machine Learning Platform. If you’d like to read it from the beginning, start here.
 4 min read | Dec 09, 2019Share:
4 min read | Dec 09, 2019Share:
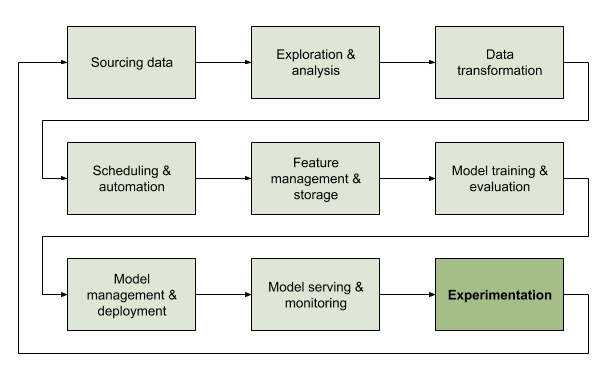
In this post, we cover the latest member of the platform. Turing is our solution to the online testing and evaluation of ML models, the final stage of the Machine Learning Lifecycle which closes the loop.
ML is hard, ML testing is harder
Verifying the correctness of software is a difficult but important task, and for ML systems this is particularly challenging. ML systems typically have behaviour that is difficult to define (i.e., the “Test Oracle Problem”) and the inputs are complex to simulate (e.g., they are stateful or depend on other ML systems).
Many teams choose to ignore this hard problem and assume that the ML systems are not testable. It is only fair to note this is not constrained to ML practitioners but also frequent in areas such as infrastructure engineering, which also suffers the challenge of complex inputs. This is a situation that upsets the rigorous software engineer.
There are various ways of dividing up the ML testing problem. Looking at the problem through the lens of the ML Lifecycle, we see ML testing as a series of stages:
1. Validating the training data pre-training
2. Offline evaluation of models during training
3. Validating the deployed models and their input data post-training and pre-inference
4. Validating the deployed models and their input data during inference
5. Online evaluation of the models post-inference
Put differently, the ML testing problem is one of validating the data and the other of the models, both of which are important at different times.
Data validation, at minimum, is about measuring various aspects of the input data and ensuring it stays within certain parameters. This could include the amount of data, latency of real-time data feeds, presence of missing values, and statistical distribution of the data. More sophisticated validations could consider things like adversarial inputs. We will want to perform these checks on the training data and the inference inputs.
Likewise, testing models could be done simply or with greater sophistication. Data scientists would typically perform an offline evaluation of the model, using metrics such as precision-recall, area-under-curve (AUC), or mean-squared error (MSE). ML engineers might smoke test the model during deployment with a fixed input set and verify that it completes the inference and produces output with the correct fields and values.
Introducing Turing
At Gojek, data validation pre-training and during inference happens via Feast. Validation of the models right after their deployment is handled via Merlin. Turing monitors the models during their operation and provides online evaluation metrics.
Turing bridges the backend systems that power our mobile app experience and the ML systems that imbue the intelligent functionality. Turing also integrates with Litmus, which is Gojek’s experimentation system, and Merlin, our ML Platform model management/deployment system, to provide a seamless experience for our users. Like Merlin, it shares the same preprocessing system, which supports feature enrichment through Feast.
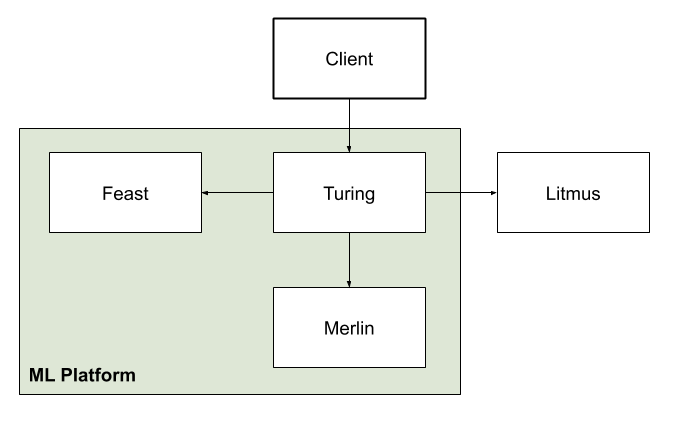
Before we dive deeper, let us outline some basic terminology:
- Client: The application or web service calling Turing.
- Ensemble: We use the ML definition of ‘ensemble’ which means some means of combining the output of multiple models to obtain better performance. Some well-known techniques including bagging, boosting, and stacking.
- Experiment: A test, using real input data, to evaluate which treatment is most effective.
- Outcome: The final result of the experiment, e.g., user conversions, driver wait time, order completion rates.
- Response: The specific values we are returning in reaction to the client’s request, e.g, the surge pricing multiplier, the ID of the driver to dispatch. In this post, “response” will not refer to how the user reacts to the treatment.
- Rule: The conditions determining which treatment to apply to a specific unit. Rules may consider the unit ID, time or place of the request, customer segment (new user, power user). They are typically deterministic: given a unit ID, they will typically return the same treatment.
- Treatment: The part that the data scientists control and vary and it could be a model or an ensemble of models. The treatment will compute the response.
- Unit: The smallest entity that can receive different treatments, e.g., a user, driver, session, or order.
Turing’s machinery
Turing currently boasts the following features:
- Low-latency, high-throughput traffic routing to an unlimited number of ML models.
- Experimentation rules based on incoming requests to determine the treatment to be applied. The rule engine is currently Litmus.
- Feature enrichment of incoming requests through Feast.
- Dynamic ensembling of models for each treatment. A treatment does not have to be just a single model.
- Reliable and safe fallbacks in case of timeouts.
- Simple response and outcome tracking.
At its heart, Turing is an intelligent traffic router with several extension points that provide key functionality: a rule engine, and preprocessing and post-processing stages.
- Rule engine: Turing implements a Litmus client, and may in future support Facebook’s PlanOut for dynamic policies and the possibility of generating policies based on experiment outcomes, e.g., for multi-armed bandits or circuit breakers. In Turing, the rule engine receives a unit ID and returns an experimentation policy, based on a set of rules preconfigured by the data scientist.
An example of a simple rule would be to direct even-numbered user IDs to Treatment A and odd-numbered user IDs to Treatment B for an A/B test. Litmus itself supports rules that consider predefined customer segments, the user’s location, or the time of day. - Preprocessing: The Turing preprocessor integrates with Feast but also has the ability to perform arbitrary transformations on the incoming request. We expect this to be used for feature enrichment, e.g., given a user ID in the request, look up the past transaction history for the user.
- Post-processing: We currently support a basic ensembler that can compute a linear combination of model outputs or, in the trivial case, map each treatment to a model. The ensembling is controlled by the policy from the rule engine. Data scientists can implement more complex ensembling too.
The traffic flow is as such:
A) Incoming requests from the client are parsed to extract the experiment unit (e.g, a user, session, or order)
B) the unit ID is passed to a rules engine to determine the treatment.
C) Simultaneously, the request is sent to a preprocessing stage to enrich the request with features.
D) The preprocessed request is forwarded to all models at the same time.
E) Responses from models are collected and sent to the post-processor, where it ensembles the request based on the policy from the rules engine.
F) Finally, a tracking ID is appended to the ensembled response and it is logged (together with the individual model responses and the original request) as it is returned to the client.
G) Later, it is the client’s responsibility to log the outcome with the tracking ID.
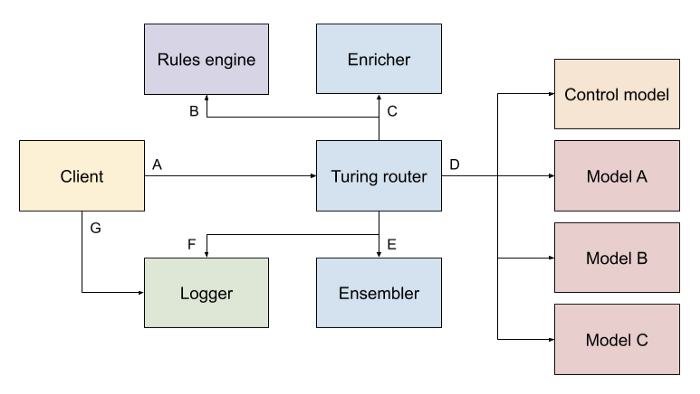
Most of the traffic is dispatched asynchronously to minimise latencies. For example, we request the ensemble configuration from the rules engine before the models are even run, though the ensemble configuration is only needed later. Also note that we dispatch requests to all models regardless of their contribution to the final response. One of these models would be a simple but reliable fallback, e.g., always returns a fixed default value. If any of the models time out or fail, we would thus be able to quickly return a fallback result without further delay.
Data scientists to determine the effectiveness of each treatment via request-level logging: For each request, the client will eventually log the tracking ID and the experiment outcome, e.g., order completed, widget clicked. Turing will combine these client logs with its internal logs, using the tracking ID as the join key. Litmus provides a UI to view such experiment results visually. The outcomes here may also be fed back to the rules engine when implementing reinforcement learning systems.
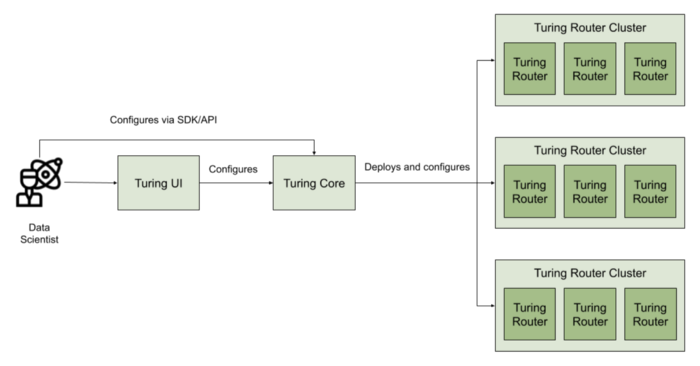
Each Turing deployment is an auto-scaling router cluster meant to support a single type of request. For example, one router cluster would handle calculating the surge factor for pricing rides and another cluster would serve food recommendations. The router clusters are centrally managed via the Turing core, which itself is part of our ML Platform. This means data scientists can interact via the Python SDK or Web UI to set up and monitor all their experiments in one place.
Each deployment comprises a router cluster and its associated YAML configuration generated by the core. The Turing router is built on our Fiber traffic routing library written in Golang, and sources its configuration when it starts up. An example configuration would look like this:
This means that changing any of the extension points (rules engine, pre- or post-processor) or any of the model endpoints will require a re-deployment. However, changes to the rules themselves, or changes to the models behind the endpoints via Merlin’s support for versions will not incur any downtime.
What’s next
Turing is very young and is currently used on a small number of projects at Gojek, but it has been designed to replace the custom-built experimentation systems in some of our largest ML systems (such as the pricing engine and driver dispatch system). These projects involve more sophisticated experimentation setups including switchback experiments and contextual bandits that can be implemented via Turing’s extension points. These systems also require circuit breakers, which can be implemented via the rule engine and ensembler, in cases where new models misbehave and damage the business.
To make Turing performant for such mission-critical systems, we have the possibility of moving some of the extensions in-process to minimise the latencies of additional network hops. But another option is to move Turing’s routing logic from its current standalone Golang binary and embed it directly into our Kubernetes service mesh, which is based on Istio, saving another hop.
Turing will also be better integrated with Merlin and Litmus. The improved Turing UI will make it easier to set up experiments in Litmus, configure the relevant model endpoints from Merlin, and then view the experiment outcomes in the upcoming Litmus results UI.
That’s all from us for now. Hope you found this series useful. We’re always working on building things, and documenting it all. Keep watching this space for more. Until next time!
Contributions from:
Krithika Sundararajan, Roman Wozniak

